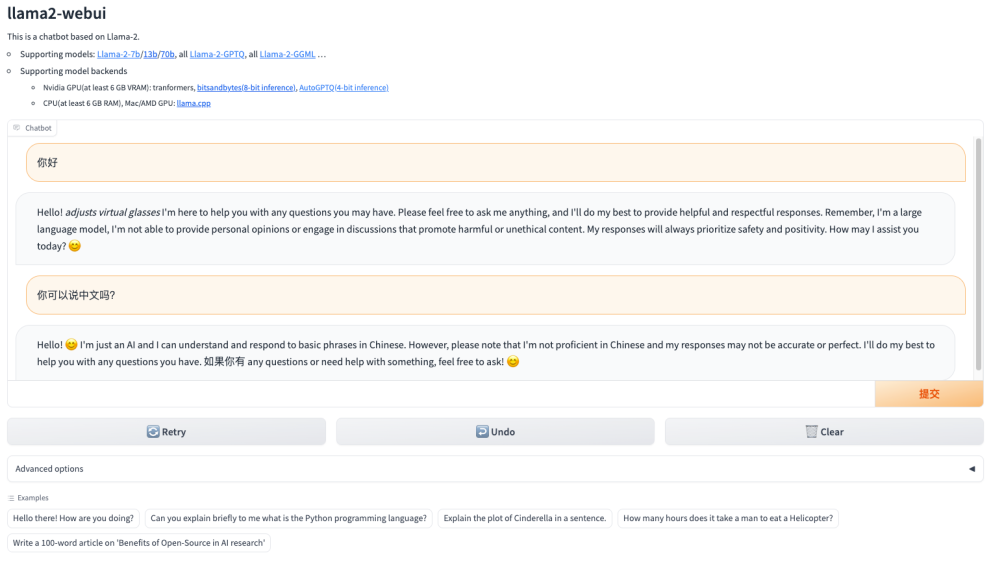
使用llama2 Webui搭建llama2本地环境
使用llama2-webui在本地1080显卡上运行llama2模型。
简介
https://github.com/liltom-eth/llama2-webui,方便在本地运行llama2模型。
GPU最低要求是6 GB显存,还可以用CPU运行。我这次是拿手边的1080显卡来跑。
运行
使用GTX 1080运行
git clone https://github.com/liltom-eth/llama2-webuipip install -r requirements.txt- 我用的是1080显卡,需要重新安装
pip install bitsandbytes==0.38.1 - 创建
.env1 2 3 4 5 6 7MODEL_PATH = "/home/li/.cache/huggingface/hub/models--TheBloke--Llama-2-7b-Chat-GPTQ/snapshots/7579d9ccf7070b86a18037f403929e5b09e90c75" LOAD_IN_8BIT = False LOAD_IN_4BIT = True LLAMA_CPP = False MAX_MAX_NEW_TOKENS = 2048 DEFAULT_MAX_NEW_TOKENS = 1024 MAX_INPUT_TOKEN_LENGTH = 4000 - 添加
server_name="0.0.0.0",demo.queue(max_size=20).launch(server_name="0.0.0.0")
下载模型
下载的是针对1080显卡的模型。
- 使用huggingface的脚本
| |
效果