Whisper的使用
使用whisper进行语音识别。利用 M1 芯片和 NVIDIA 显卡进行加速。
简介
项目官网:https://github.com/ggerganov/whisper.cpp
Whisper.cpp 是 OpenAI Whisper 模型的一个实现,可以在本地进行语音识别。
安装
- 克隆代码库:
git clone https://github.com/ggerganov/whisper.cpp.git - 构建:
make
使用
下载模型
./models/download-ggml-model.sh small,small是模型的名称。可以在 Hugging Face 查看可用的模型,https://huggingface.co/ggerganov/whisper.cpp/tree/main。带
.en后缀的模型只支持英文。识别
./main -m models/ggml-small.bin --language zh -f path/to/test.wav
注意:音频文件需要是单声道的,可以使用ffmpeg转换。ffmpeg -i b.mp4 -f wav -ar 16000 -ac 1 test.wavc
m1加速
可以利用 Mac 的 M1 芯片进行加速,试下来速度非常快。
创建python环境
1 2 3pip install ane_transformers pip install openai-whisper pip install coremltools在环境变量中添加
coremlc- 先安装xcode
- 在
PATH中添加/Applications/Xcode.app/Contents/Developer/usr/bin
构建
make cleanWHISPER_COREML=1 make -j
创建专用模型
- 下载模型:
./models/download-ggml-model.sh base - 转换模型:
./models/generate-coreml-model.sh base - 这两个模型的名称要相同,就相当于把base模型转为coreml可以用的
- 下载模型:
运行:
./main -m models/ggml-base.bin --language zh -f path/to/test.wav
cuda加速
如果有navida的显卡,也可以借助cuda来加速。我的环境是ubuntu22.04,显卡是NVIDIA GeForce GTX 1080。
ubuntu-drivers devices,查看gpu设备和驱动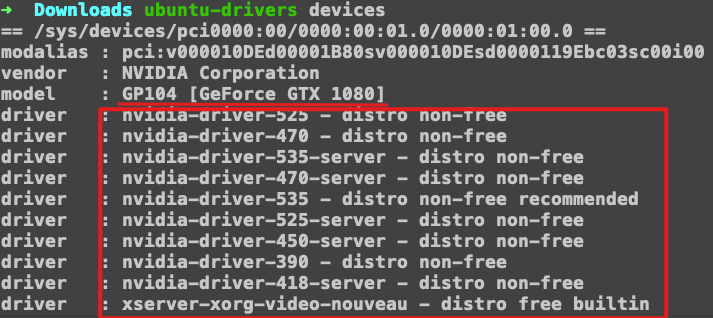
红框中的内容是可用的驱动。
安装驱动:
sudo apt install nvidia-driver-535重启计算机。
查看驱动是否安装成功:
nvidia-smi安装 Anaconda 或 Miniconda,方便管理 Python 环境,并方便安装 CUDA 和 cuDNN。
创建python环境,安装cuda和cudnn
conda install cudnn=7.6.0conda install cudatoolkit=10.0.130conda install cuda==11.4.0 -c nvidia
修改Makefile

修改两处红框:
- 添加上新建环境的lib文件夹。
- 对于 GTX 1080 显卡,可以使用 sm_61,可以运行
nvcc --help查看支持的gpu-architecture
make cleanWHISPER_CUBLAS=1 make -j成功运行
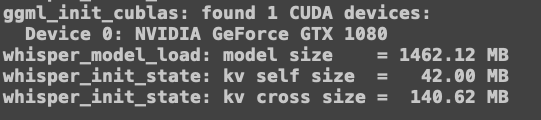
如果配置成功,运行时会显示显卡信息。
可能遇到的问题
构建成功之后运行报错:*.so'没有找到
在$LD_LIBRARY_PATH中添加上conda环境的lib 路径,就是Makefile里面的。
构建成功之后运行报错:CUDA error 35
CUDA error 35 at ggml-cuda.cu:1835: CUDA driver version is insufficient for CUDA runtime version。
这个是cuda和显卡驱动不匹配,方法是卸载掉所有的驱动,然后安装最新的驱动。再查看一下匹配的cuda和cudnn版本。