Pandas常用方法
记录一些pandas常用的操作,会持续更新
1.创建Dataframe
| |
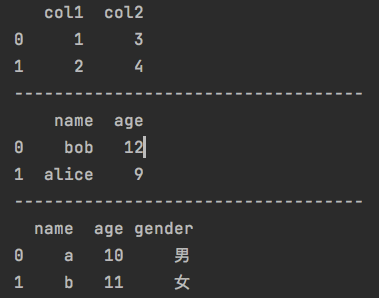
2.cannot reindex from a duplicate axis报错
df[df.index.duplicated()]
获取index重复的行。
删除重复的行:
df.drop_duplicates(subset=['nav_date'], inplace=True),删除nav_date列重复数据的行。
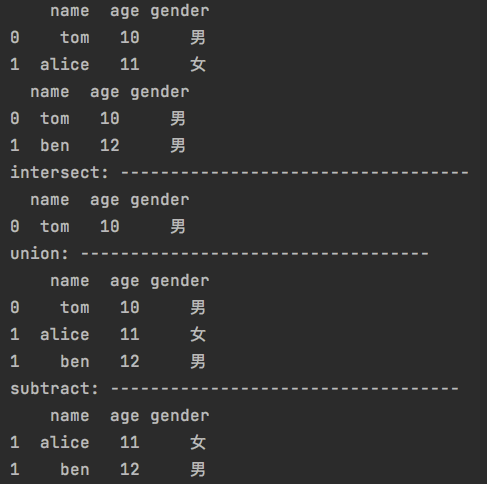
3.交并补
| |
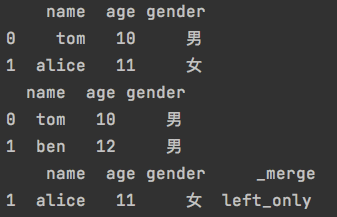
4.df1不在df2中的数据
| |
5.date_range
可以创建一段连续的时间数据
| |

freq还有很多种格式,具体参考:https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#timeseries-offset-aliases
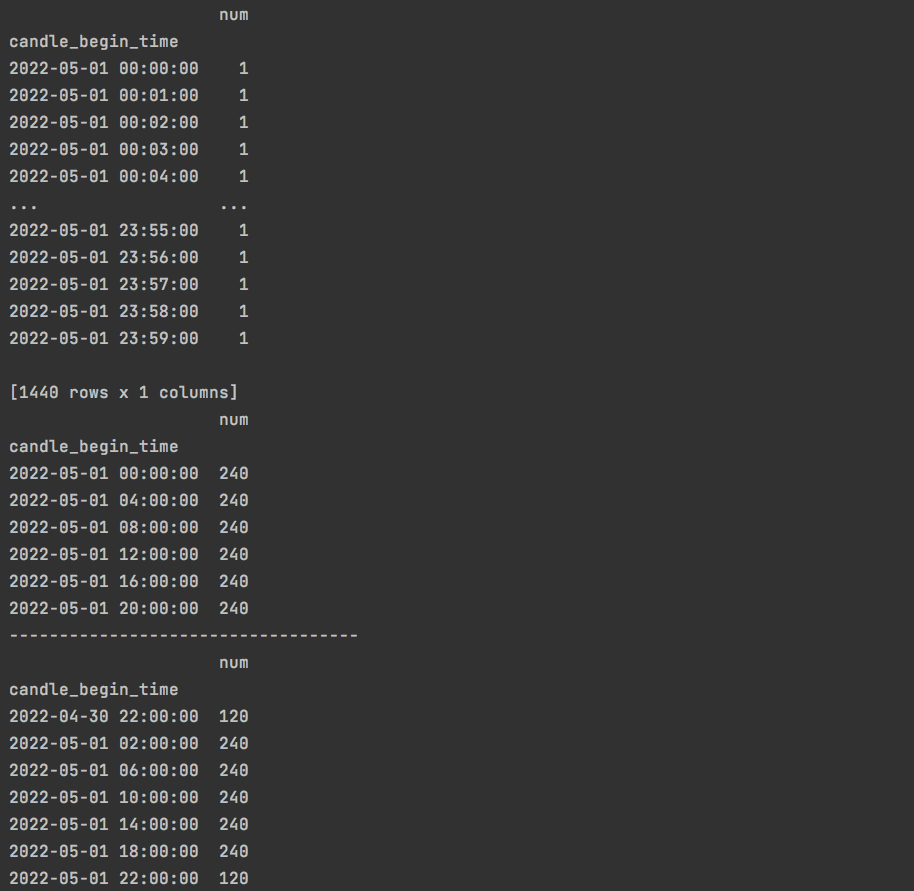
6.resample
时间序列重构,可以对时间重新采样。
使用要点:
- dataframe的index需要是DateIndex
- 新版本的pandas推荐使用offset代替base,offset写的时候需要带上时间单位,也是参考data_range的freq即可。
| |
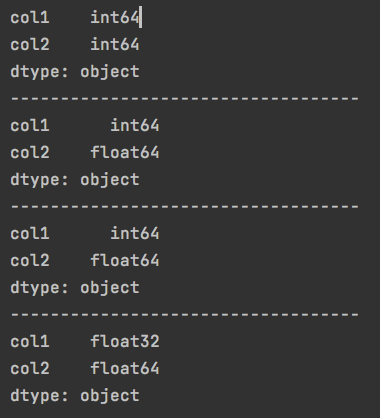
7.数据类型转换
把string类型的列转换为float
| |
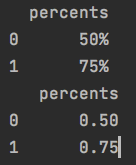
8.百分比字符串转为float
| |
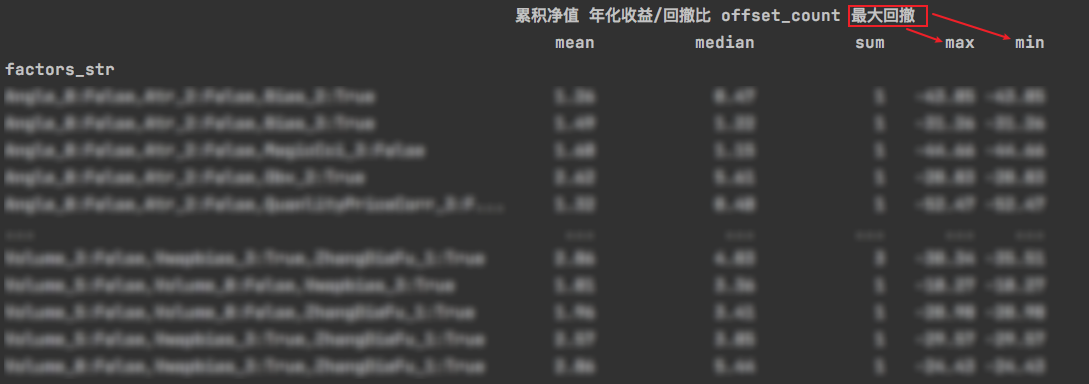
9.aggregate多个
groupby之后用agg操作的话,是可以指定数组来计算的。
| |
10.Cannot index with multidimensional key
如9中的dataframe,column是有两层的。这时候直接df.loc[df['offset_count'] == 1]也是操作不了的,会报错。
有几种方法来对column进行操作。
1.get_level_values
| |

2.to_flat_index
| |

3.map
| |

4.to_flat_index& lambda
| |

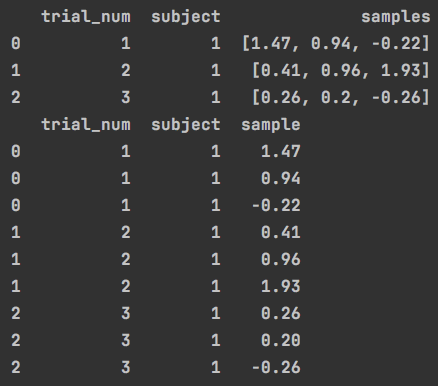
11.把一列数组转换为多行
| |
12.筛选某一列值重复2次以上的行
| |
13.导出到excel时附带超链接
| |
14.判断列数据是否都为nan
| |